PWN学习之The House of Force
接触CTF那么久终于第一次鼓起勇气接触PWN了!!
pwn必备工具安装
https://github.com/Gallopsled/pwntools
https://github.com/pwndbg/pwndbg
https://github.com/david942j/one_gadget
The top chunk
第一步当然是熟悉一下堆栈以及malloc的工作方式
实验环境下载地址 https://www.aliyundrive.com/s/sutrieb13xL
GDB调试一个程序
进入house_of_force,使用gdb demo调试程序
用b main(break main) 给main函数下断点
r (run)运行程序
就会断在该画面下
为了防止gdb每次运行程序时都打印完整程序信息,可以使用set context-sections code来打印源码部分,使用context命令可以查看源代码
查看内存分配
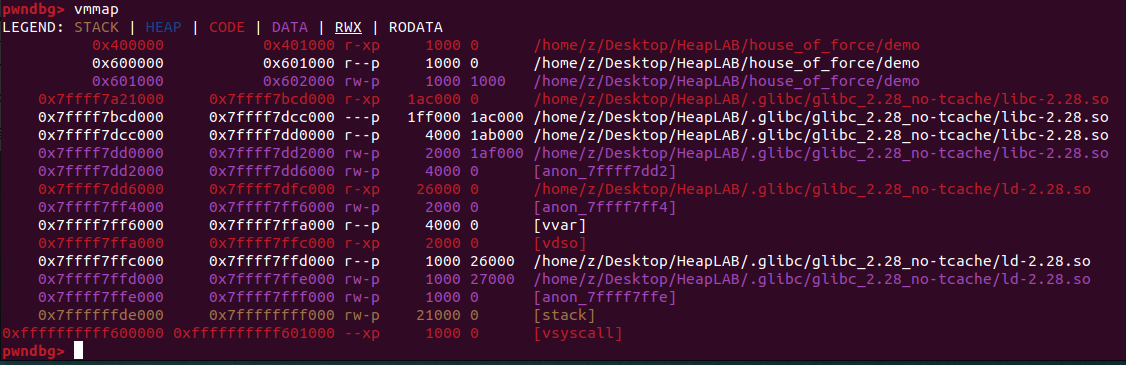
使用vmmap可以查看该程序的内存分配情况,蓝色的就是堆内存分配,可以看到目前还没有数据分配到堆中
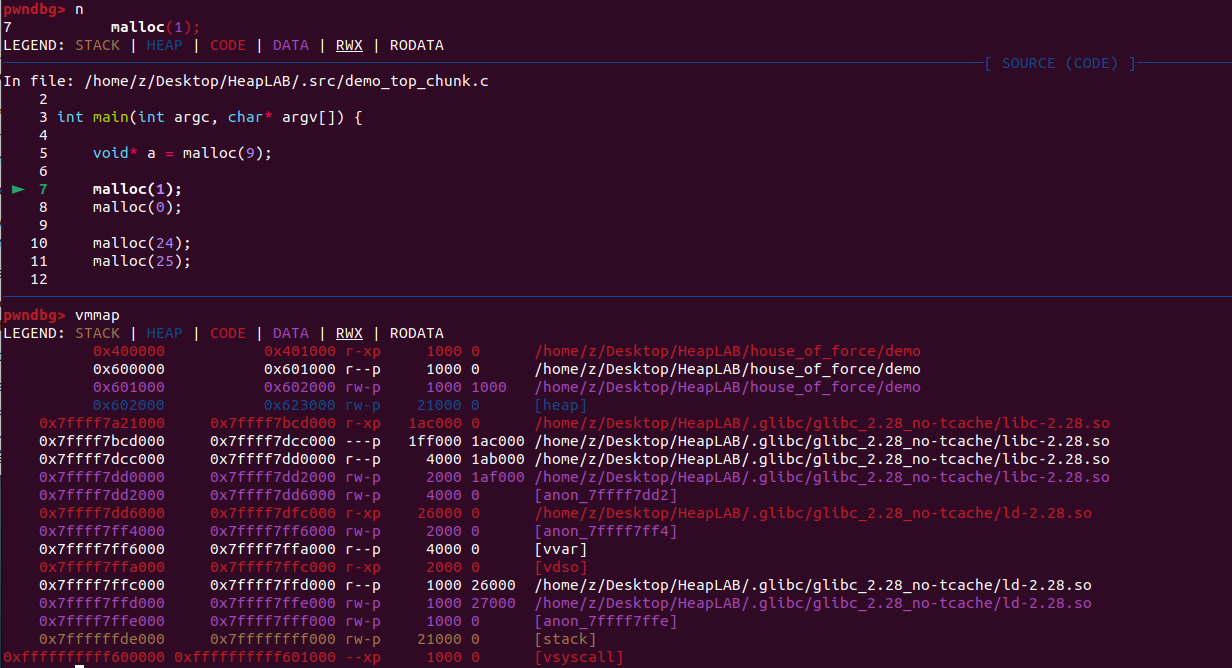
使用n(next)命令执行一行代码,再次查看可以发现堆中被分配了内存
查看堆分配
vis(vis_heap_chunks)查看堆内存分配情况,青色的地方就是本次malloc分配的空间
结合上面的原码发现,malloc并未分配9字节,而是分配了前八个inline metadata,加上后面的8*3个字节,因为这是malloc分配内存的最小单位,并以每次0x10增加,所以分配的数据 % 0x10始终为0
inline metadata也可以当作是malloc本次分配的一些基本信息,如分配的大小等。由于每次都增长0x10个空间,所以最后一位就可以用来干别的活了,在malloc中就被设计成了prev_inuse标志位,如果该标志位为1,说明这个chunk的前面一个chunk正在被使用,而第一个chunk的prev_inuse标志位始终为1,因为在此之前没有别的chunk了

连续运行多次可以发现,无论分配9个字节还是0个字节还是24个字节,每次分配的内存都是24个字节
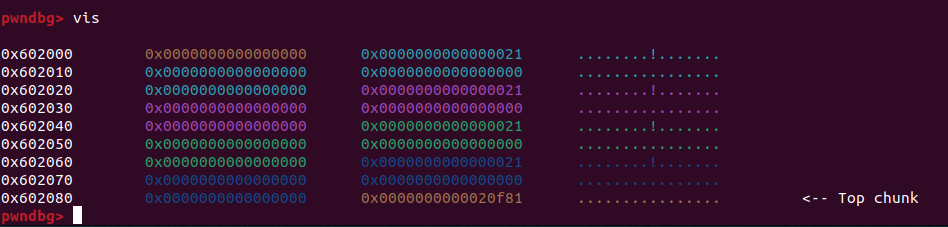
当malloc分配了25个字节时,实际上分配了0x8+0x28个空间,因为25大于24,所以必须再增加0x10个空间
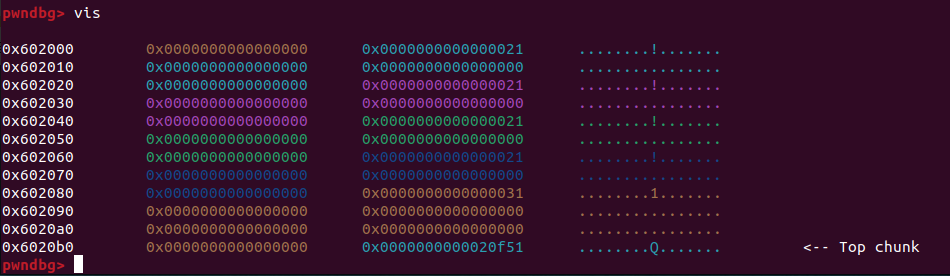
每次vis的最后都有一个Top chunk,这是malloc剩余可分配的内存空间,结合上面的图片可以很快发现,Top chunk每次减去的数量和每次分配的数量一致
1st vulnerable binary
checksec
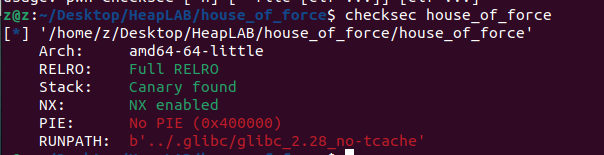
使用checksec 程序查看基本信息
Arch
运行平台及进制
RELRO
ReLocation Read-Only,为了解决延迟绑定的安全问题,将符号重定位表设置为只读,或者在程序启动时就解析并绑定所有的动态符号,从而避免GOT上的地址被篡改。
partial relro
部分开启,一些段(包括.dynamic,.got等)在初始化后会被标记为只读。
full relro
全部开启,开启Full RELRO会对程序启动时的性能造成一定的影响,但也只有这样才能防止攻击者篡改GOT。
GOT
Global Offset Table,全局偏移表/全局函数表,每一个外部定义的符号在这里有相应的条目,GOT位于ELF的数据段中,叫做GOT段。
PLT
Precedure Linkage Table,过程链接表/内部函数表,linux里的延迟绑定技术,顾名思义它就是一个过度,真正的终点还是在GOT表里。PLT表存在的原因之一是为了更高效的利用内存,且可以增加安全性
Stack
Canray是专门针对栈溢出攻击涉及的一中保护机制。由于栈溢出攻击的主要目标是通过溢出覆盖函数栈高位的返回地址,因此其思路是在函数开始执行前,即返回地址前写入一个字长的随机数据(canary),在函数返回前校验该值是否被改变,如果改变则认为是栈溢出,程序直接终止,以此来防止信息泄露。
ASLR
Address space layout randomization,地址空间布局随机化
调试程序
gdb house_of_force 打开程序
r运行
看到三个选项,选1,分配内存后使用ctrl+c中断程序,可以使用调试命令了
vis查看堆内存
输入c继续运行程序
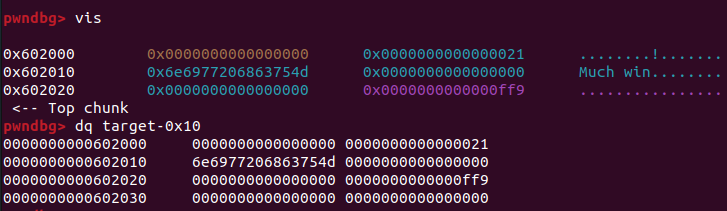
输入2,显示target内容为XXXXXXX
中断,使用dq target查看target内存,或使用xinfo target查看详细信息
使用Vim编辑器
cp pwntools_template.py xpl.py备份一下脚本
vim xpl.py打开脚本
:!./% 在vim中运行该脚本
:!./% GDB使用gdbserver调试
:!./% GDB NOASLR 禁止随机地址
!表示接下来要执行shell命令
%表示当前文件名
:[num1], [num2]d删除num1 - num2之间的行
栈溢出
在第一小节提到过malloc的top chunk表示可分配的堆大小,由于malloc没有检查输入的缓冲区大小,只要把top chunk改成最大,那么就可无限分配空间
脚本第一次执行的malloc的时候,修改成malloc(24, b"Y"*24 + p64(0xffffffffffffffff)),p64(0xffffffffffffffff)表示将其中的0xffffffffffffffff以小端序的方式填充
运行脚本,输入vis,发现已经溢出成功

如果要使用栈溢出修改target变量的值,那么就需要将malloc的下一步分配的地址定位到target前面
通过整形地址溢出的方式,计算地址的偏移量
def delta(x, y):
return (0xffffffffffffffff - x) + y
delta(heap + 0x20, elf.sym.target - 0x20)
# heap+0x20表示当前已经分配了一次最小单位的malloc
# target-0x20表示分配到target前面一个最小单位的malloc,因为运行完这次malloc,空间还会增加0x20再次分配malloc,地址就变成target地址了,原先的target内容就被覆盖了